# Optional: You don't have to run this cell if you set the environment variables above
import getpass
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
import sys
if 'google.colab' in sys.modules:
from google.colab import userdata
os.environ["LANGCHAIN_API_KEY"] = userdata.get('LANGCHAIN_API_KEY') if userdata.get('LANGCHAIN_API_KEY') else getpass.getpass("Enter your LangSmith API key:")
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY') if userdata.get('OPENAI_API_KEY') else getpass.getpass("Enter your OpenAI API key:")
else:
from dotenv import load_dotenv
load_dotenv('./.env')
if not os.environ.get('LANGCHAIN_API_KEY'):
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass("Enter your LangSmith API key:")
if not os.environ.get('OPENAI_API_KEY'):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key:")
os.environ["LANGCHAIN_PROJECT"] = "ds549-langchain-retriever" # or whatever you want your project name to beLangChain 03 – Embeddings, vector stores and retrievers
Introduction
This tutorial is based on LangChain’s “Vector stores and retrievers” tutorial and notebook.
- We’ll look at LangChain’s vector store and retriever abstractions.
- They enable retrieval of data from (vector) databases and other sources for integration with LLM workflows.
- They are important for applications that fetch data to be reasoned over as part of model inference, as in the case of retrieval-augmented generation, or RAG.
We’ll put it all together in a RAG pipeline later.
Concepts
We’ll cover retrieval of text data.
We will cover the following concepts:
- Documents
- Vector stores
- Retrievers
Setup
You can run this as a notebook in Colab: ![]()
Or you can run it locally by downloading it from our repo.
Installation
This tutorial requires the langchain, langchain-chroma, and langchain-openai packages:
pip install langchain langchain-chroma langchain-openaiconda install langchain langchain-chroma langchain-openai -c conda-forgeFor more details, see our Installation guide.
Environment Variables and API Keys
The following cell will enable LangSmith for logging and load API keys for LangChain and OpenAI.
If you are running locally, you can set your environment variables for your command shell and if you are on Colab, you can set Colab secrets.
In the code below, if the variables are not set, it will prompt you.
Documents
LangChain implements a Document abstraction, which is intended to represent a unit of text and associated metadata. It has two attributes:
page_content: a string representing the content;metadata: a dict containing arbitrary metadata.
The metadata attribute can capture information about the source of the document, its relationship to other documents, and other information.
Note that an individual
Documentobject often represents a chunk of a larger document.
Let’s generate some sample documents:
from langchain_core.documents import Document
documents = [
Document(
page_content="Dogs are great companions, known for their loyalty and friendliness.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Cats are independent pets that often enjoy their own space.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Goldfish are popular pets for beginners, requiring relatively simple care.",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="Parrots are intelligent birds capable of mimicking human speech.",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="Rabbits are social animals that need plenty of space to hop around.",
metadata={"source": "mammal-pets-doc"},
),
]Here we’ve generated five documents, containing metadata indicating three distinct “sources”.
Vector Embeddings
Vector search is a common way to store and search over unstructured data (such as unstructured text).
The idea is as follows:
- Generate and store numeric “embedding” vectors that are associated with each text chunk
- Given a query, calculate its embedding vector of the same dimension
- Use vector similarity metrics to identify text chunks related to the query
Figure Figure 1 illustrates this process.
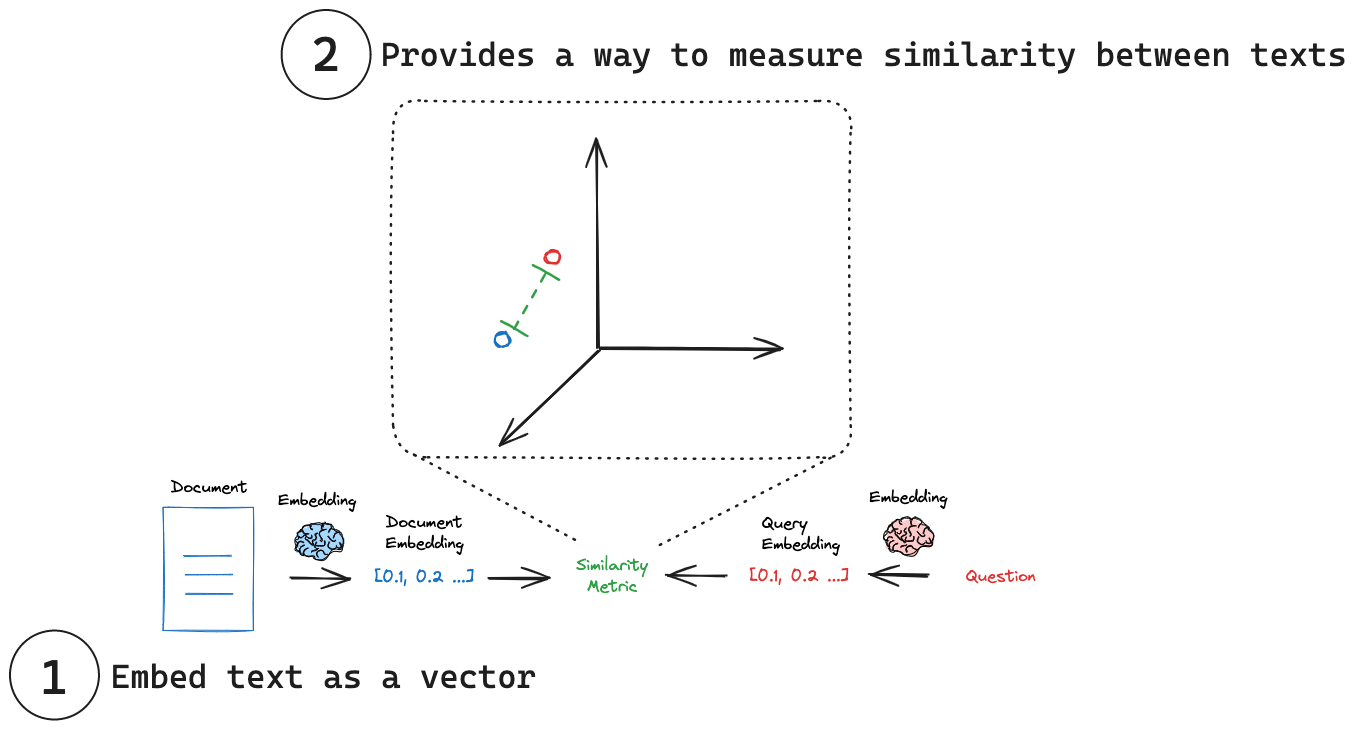
Vector Embeddings – Deeper Look
Before we continue let’s explain a bit more how we get the vector embeddings.
Starting from text, we tokenize the text string (Figure 2).
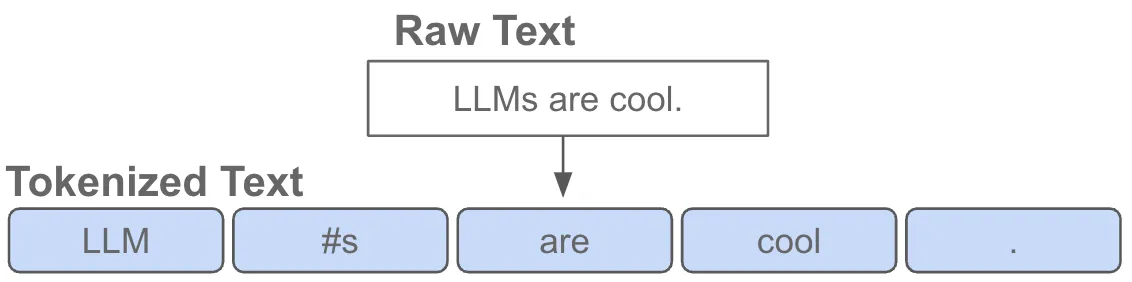
Tokenizers are trained to find the most common subwords and character groupings from a large corpus of representative text.
See Karpathy’s “Let’s build the GPT Tokenizer” YouTube viceo for an excellent tutorial building one from scratch.
Our query string is then tokenized and represented by the index of the token.
The token IDs are given to a multi-layer neural network, often a transformer architecture, which goes through a set of transforms (Figure 3).
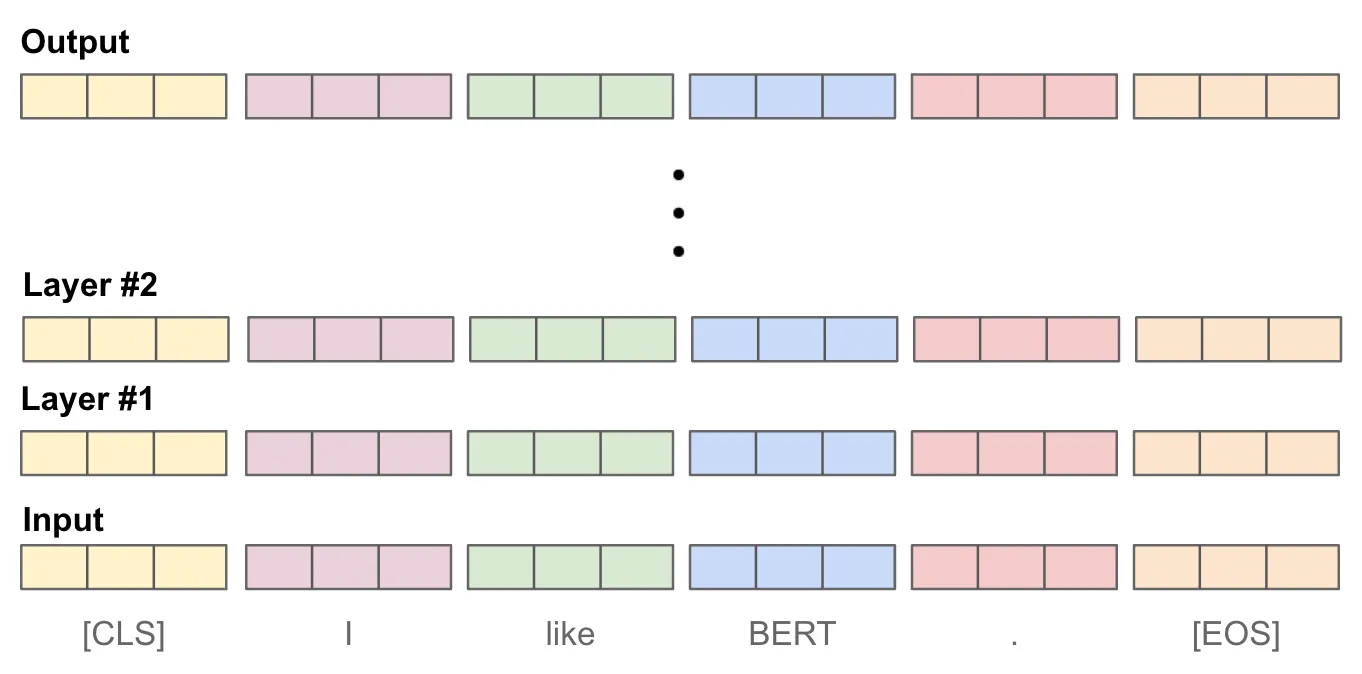
The model is trained to associate similar text strings (Figure 4).
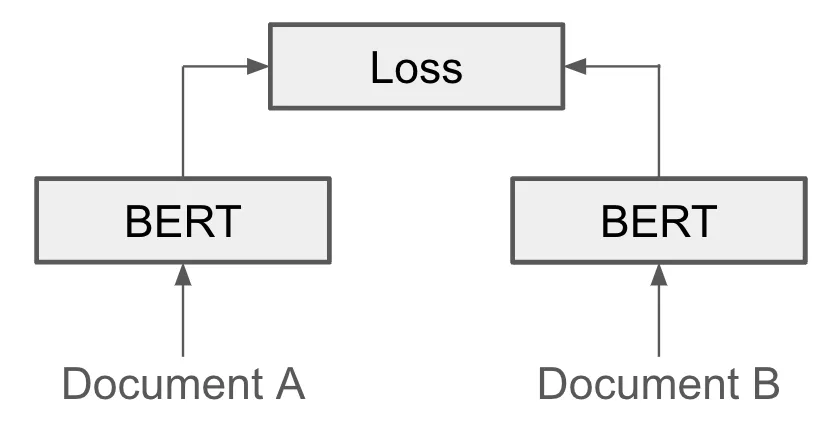
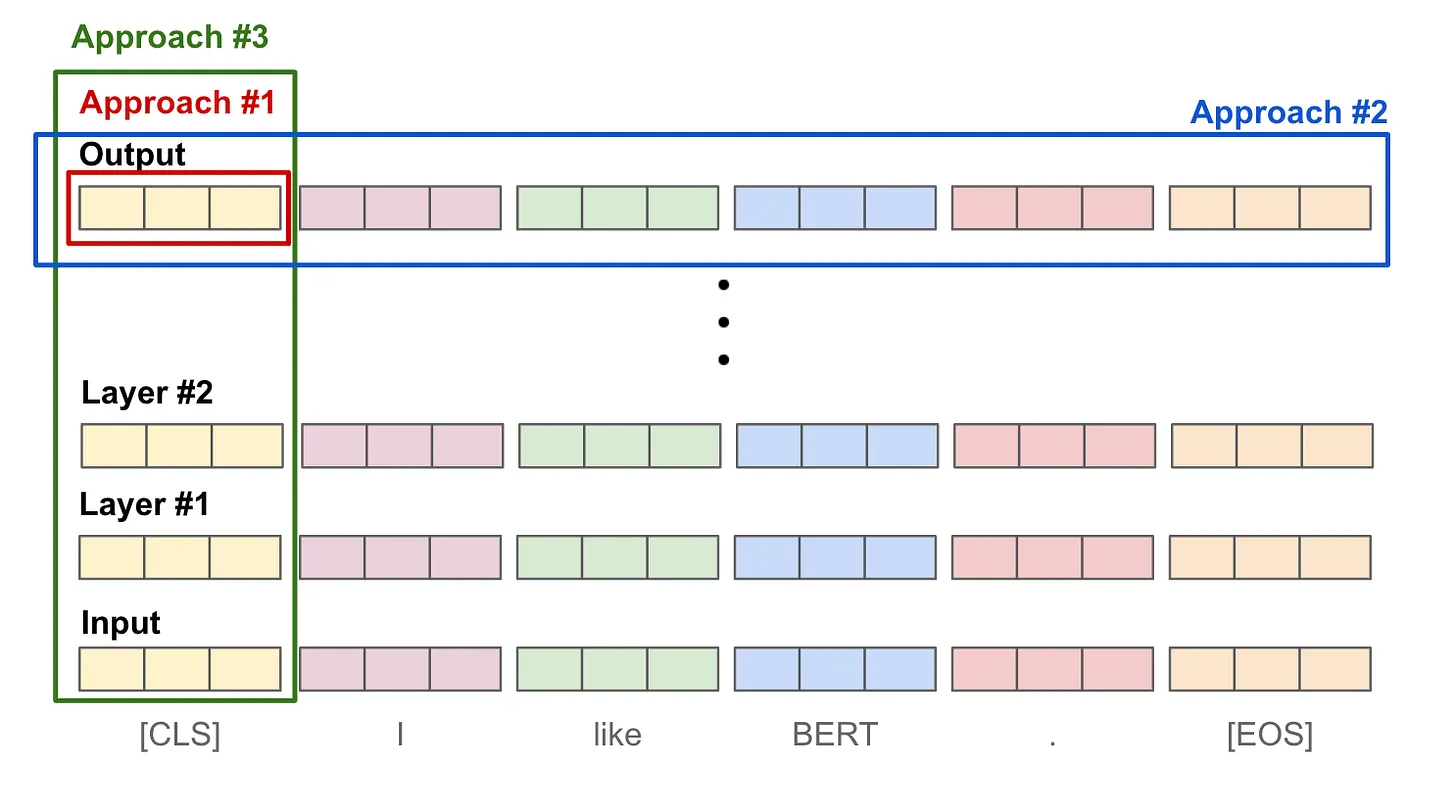
But we need one embedding vector for any arbitrary length text, and so to do that we combine the output token in for example (Figure 5)
- Approach #1: Use the final output
[CLS]token representation. - Approach #2: Take an average over the output token vectors.
- Approach #3: Take an average (or max) of token vectors across layers.
See this blog for a nice overview of vector search.
Vector Stores
The embedding vectors and associated document chunks are collected in a vector store.
LangChain VectorStore objects contain:
- methods for adding text and
Documentobjects to the store, and - querying them using various similarity metrics.
They are often initialized with embedding models, which determine how text data is translated to numeric vectors.
LangChain Vector Store Integrations
LangChain includes a suite of integrations that wrap different vector store types:
- hosted vector stores that require specific credentials to use;
- some (such as Postgres) run in separate infrastructure that can be run locally or via a third-party;
- others can run in-memory for lightweight workloads.
We will use LangChain VectorStore integration of Chroma, which includes an in-memory implementation.
Instantiate a Vector Store
To instantiate a vector store, we usually need to provide an embedding model to specify how text should be converted into a numeric vector.
Here we will use LanhChain’s wrapper to OpenAI’s embedding models.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
# dimensions=1024 # you can optionally specify dimension
)
print(embeddings)
vectorstore = Chroma.from_documents(
documents,
embedding=embeddings,
)
print(vectorstore)client=<openai.resources.embeddings.Embeddings object at 0x7fb8a1b40140> async_client=<openai.resources.embeddings.AsyncEmbeddings object at 0x7fb8a1bfc740> model='text-embedding-3-small' dimensions=None deployment='text-embedding-ada-002' openai_api_version=None openai_api_base=None openai_api_type=None openai_proxy=None embedding_ctx_length=8191 openai_api_key=SecretStr('**********') openai_organization=None allowed_special=None disallowed_special=None chunk_size=1000 max_retries=2 request_timeout=None headers=None tiktoken_enabled=True tiktoken_model_name=None show_progress_bar=False model_kwargs={} skip_empty=False default_headers=None default_query=None retry_min_seconds=4 retry_max_seconds=20 http_client=None http_async_client=None check_embedding_ctx_length=True
<langchain_chroma.vectorstores.Chroma object at 0x7fb8a1bfef00>Calling .from_documents here will add the documents to the vector store.
VectorStore implements methods (e.g. add_texts() and add_documents() for adding documents after the object is instantiated.
Most implementations will allow you to connect to an existing vector store e.g., by providing a client, index name, or other information.
See the documentation for a specific integration for more detail.
Querying a Vector Store
Once we’ve instantiated a VectorStore that contains documents, we can query it. VectorStore includes methods for querying:
- Synchronously and asynchronously;
- By string query and by vector;
- With and without returning similarity scores;
- By similarity and maximum marginal relevance (to balance similarity with query to diversity in retrieved results).
The methods will generally include a list of Document objects in their outputs.
Examples
Return documents based on similarity to a string query:
vectorstore.similarity_search("cats")[Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.')]To make it more interesting, here’s a search string that doesn’t use the word “cats”.
vectorstore.similarity_search("Tell me about felines.")[Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.')]Async query:
await vectorstore.asimilarity_search("cat")[Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.')]Return distance scores:
# Note that providers implement different scores; Chroma here
# returns a distance metric that should vary inversely with
# similarity.
vectorstore.similarity_search_with_score("cat")[(Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
1.2405281066894531),
(Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
1.550061821937561),
(Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
1.6290202140808105),
(Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.'),
1.7067742347717285)]Again, let’s be a bit more obtuse in our query string.
vectorstore.similarity_search_with_score("I want to know about tabby and persians.")[(Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
1.254130244255066),
(Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.'),
1.607422947883606),
(Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
1.6193156242370605),
(Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
1.653489351272583)]We can calculate the embedding ourselves and then search documents:
embedding = OpenAIEmbeddings().embed_query("cat")
vectorstore.similarity_search_by_vector(embedding)[Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.'),
Document(id='ed9bdea8-ad74-44d1-b35e-244426a451eb', metadata={'source': 'mammal-pets-doc'}, page_content='Cats are independent pets that often enjoy their own space.'),
Document(id='da9bb5ad-e6c3-4749-ad4f-ab611c6d149c', metadata={'source': 'mammal-pets-doc'}, page_content='Rabbits are social animals that need plenty of space to hop around.'),
Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.')]To dig deeper:
Retrievers
LangChain’s VectorStore objects cannot be directly incorporated into LangChain Expression language chains because they do not subclass Runnable.
LangChain provides Retrievers which are Runnables and can be incorporated in LCEL chains.
They implemement synchronous and asynchronous invoke and batch operations.
Vector Store .as_retriever
Vectorstores implement an as_retriever method that will generate a Retriever, specifically a VectorStoreRetriever.
These retrievers include specific search_type and search_kwargs attributes that identify what methods of the underlying vector store to call, and how to parameterize them.
For example. let’s provide a list of queries:
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
retriever.batch(["Tell me about huskies, retrievers and poodles.", "I want to swim with sharks"])[[Document(id='30d50243-a332-4c33-a489-cf995dbde27f', metadata={'source': 'mammal-pets-doc'}, page_content='Dogs are great companions, known for their loyalty and friendliness.')],
[Document(id='f0377098-5bed-4bdb-8470-37216f460ff9', metadata={'source': 'fish-pets-doc'}, page_content='Goldfish are popular pets for beginners, requiring relatively simple care.')]]VectorStoreRetriever supports search types of:
"similarity"(default),"mmr"(maximum marginal relevance, described above), and"similarity_score_threshold".
We can use the latter to threshold documents output by the retriever by similarity score.
RAG – First Look
Retrievers can easily be incorporated into more complex applications, such as retrieval-augmented generation (RAG) applications that combine a given question with retrieved context into a prompt for a LLM. Below we show a minimal example.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
message = """
Answer this question using the provided context only.
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_messages([("human", message)])
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llmresponse = rag_chain.invoke("tell me about cats")
print(response.content)Cats are independent pets that often enjoy their own space.Vector Store from Web Pages
This is a more realistic example, where we fetch content from a set of web pages and then create a vector store from them.
This is a work in progress.
import requests
from bs4 import BeautifulSoup
from langchain_core.documents import Document
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# Step 1: Fetch content from URLs
urls = [
"https://trgardos.github.io/ml-549-fa24/01_command_shells.html",
"https://trgardos.github.io/ml-549-fa24/02_python_environments.html",
"https://trgardos.github.io/ml-549-fa24/03_git_github.html",
"https://trgardos.github.io/ml-549-fa24/04_scc.html",
"https://trgardos.github.io/ml-549-fa24/07_scc_cont.html",
"https://trgardos.github.io/ml-549-fa24/08_scc_batch_computing.html",
"https://trgardos.github.io/ml-549-fa24/10-pytorch-01.html",
"https://trgardos.github.io/ml-549-fa24/12-pytorch-02-dataloaders.html",
"https://trgardos.github.io/ml-549-fa24/13-pytorch-03-model-def.html",
"https://trgardos.github.io/ml-549-fa24/14-pytorch-04-autograd.html",
"https://trgardos.github.io/ml-549-fa24/15-pytorch-05-training.html",
"https://trgardos.github.io/ml-549-fa24/16-lc01-simple-llm-app.html",
"https://trgardos.github.io/ml-549-fa24/17-lc02-chatbot.html",
"https://trgardos.github.io/ml-549-fa24/18-lc03-retrievers.html"
# Add more URLs as needed
]
documents = []
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
text = soup.get_text()
documents.append(Document(page_content=text, metadata={"source": url}))print(documents)
# print(documents[0].page_content)
print(len(documents))# Step 2: Generate embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")# Step 3: Create a vector store
vectorstore = Chroma.from_documents(documents, embedding=embeddings)vectorstore.similarity_search_with_score("What is a command shell?", k=8)vectorstore.similarity_search_with_score("Where can I learn about PyTorch tensors?", k=8)Alternative: Vector Store from Web Pages
This part is also a work in progress.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(urls)
docs = loader.load()print(docs)
print(len(docs))vectorstore = Chroma.from_documents(docs, embeddings)vectorstore.similarity_search_with_score("What is a command shell?", k=8)vectorstore.similarity_search_with_score("Where can I learn about PyTorch tensors?", k=8)retriever = vectorstore.as_retriever(search_kwargs={"k": 1})response = rag_chain.invoke("What is a command shell?")
print(response.content)Learn more:
See LangChain’s retrievers section of the how-to guides which covers these and other built-in retrieval strategies.